Comprender el Producto Interno Bruto (PIB) es crucial para analizar y evaluar la economía de un país. Este indicador económico suma el valor de todos los bienes y servicios producidos dentro de un país en un periodo específico, ofreciendo una perspectiva global de la salud económica nacional. Sin embargo, el PIB enfrenta críticas por no medir aspectos como el bienestar social o el impacto ambiental. En este artículo, desglosaremos la definición, importancia y métodos de cálculo del PIB, proporcionando un entendimiento claro de este complejo concepto económico.
Definición de PIB
El PIB o Producto Interno Bruto, se define como la suma o valor total de los bienes y servicios producidos por una economía en un periodo determinado de tiempo. El PIB generalmente se mide en periodos trimestrales o anuales.
Se calcula sumando cuatro componentes: el consumo, que representa el gasto de los hogares, la inversión que representa el gasto generado para producir más bienes y servicios, las compras del gobierno y el valor neto de la diferencia entre los bienes exportados e importados. En este sentido, existen dos métodos alternativos para medir el PIB que se verán más adelante.
PIB = consumo + inversión + compras del gobierno + (exportaciones – importaciones)
La expresión matemática del PIB es: PIB = C + I + G + (Xp-Ip)
El siguiente video presenta una definición del concepto de PIB, su utilidad y medición.
La siguiente imagen aporta algunos elementos que engloban la definición de Producto Interno Bruto:
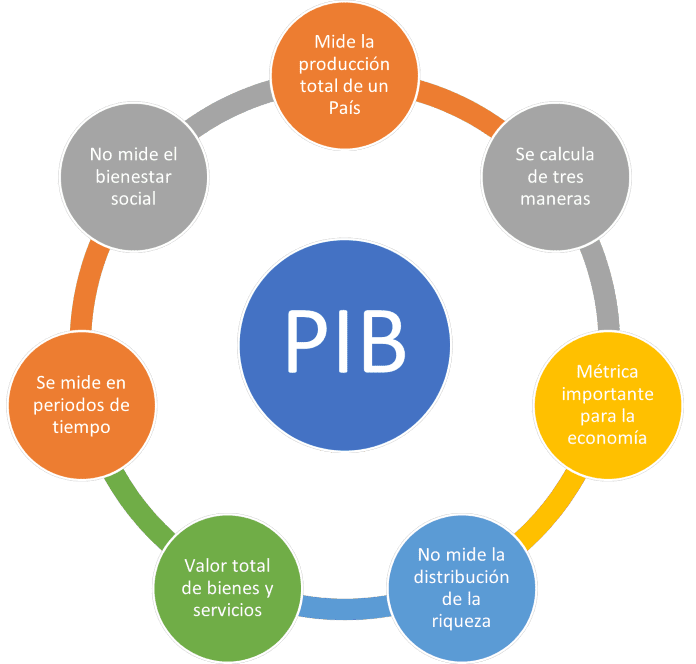
Elementos que aportan a la definición de Producto Interno Bruto
Importancia del PIB
El PIB es un indicador importante porque mide el impulso y el valor de la actividad económica, y es relevante debido a que nos ayuda a entender las variaciones de la economía en general a través del tiempo.
Al desglosar el concepto de Producto Interno Bruto encontramos que el PIB es:
- Producto porque suma la cantidad de bienes y servicios producidos.
- Interno porque solo considera lo producido dentro del territorio nacional.
- Bruto porque no considera el consumo intermedio o los bienes comprados para producir.
Críticas al PIB
Entre las críticas a la utilización del PIB como forma de medir la actividad económica encontramos:
- No mide los trabajos no remunerados o domésticos en la sociedad.
- Deja de contabilizar partes de la economía familiar y no tiene en cuenta el rol de la mujer en temas como la crianza, la educación y el apoyo familiar.
- No es un indicador de calidad sino de cantidad.
- No tiene en cuenta indicadores sociales como salud, educación, bienestar social o accesos a cuestiones básicas en la sociedad.
- No indica la distribución de la riqueza y su efecto en el bienestar general.
- Carece en sus cuentas del impacto al medioambiente y la destrucción de los recursos naturales.
A continuación encontrarás un video que ofrece el concepto de PIB y que brinda una argumentación en contra de la propuesta de eliminar el indicador como forma de medir la actividad económica en México.
Conceptos de Producto Interno Bruto PIB de varios autores
Mankiw define el producto interior bruto como: “el valor de mercado de todos los bienes y servicios finales producidos en un país durante un periodo determinado de tiempo” (2009, p. 352), y añade que: “mide la renta total y el gasto total de una economía. Como el PIB es el indicador más genérico de la situación económica general, es el punto de partida lógico para analizar el ciclo económico” (2014, p. 399).
Otra definición que enfatiza el aspecto de territorialidad del concepto es aportada por Rache de Camargo (p. 140), quien afirma que es la suma monetaria de los bienes y servicios finales producidos internamente en un país en un periodo de tiempo determinado; es decir, hay que sumar lo que se produce dentro del territorio nacional.
Sachs (2013, p. 26 y p. 49), en su definición, afirma que el producto interno bruto (PIB) es el valor total de la producción corriente de bienes y servicios finales dentro del territorio nacional, durante un periodo dado, normalmente un trimestre o un año, y complementa que captura la producción corriente de bienes finales valorizada a precios de mercado. Producción corriente significa que no se considera la reventa de artículos producidos en un periodo anterior.
Dornbusch, Fisher y Startz (2013, p. 15 y p. 17), afirman que el PIB es el valor monetario de todos los bienes y servicios finales producidos en un país en un determinado periodo. Comprende el valor de los bienes producidos, como casas y discos compactos, y el valor de los servicios, como viajes en avión y lecciones de economistas. La producción de todo lo anterior se mide a su valor en el mercado y los valores se suman para dar el PIB. Además, afirman:
- El PIB es el valor de todos los bienes y servicios finales producidos en el país en determinado periodo.
- El PIB es la suma de todos los pagos de los factores.
- El trabajo es el principal factor de producción.
Origen del indicador
El concepto moderno y el origen del PIB se atribuyen a Simon Kuznets, economista ruso-americano que trabajó en el tema de cuentas nacionales y distribución del ingreso en el contexto de la gran depresión en los Estados Unidos, que se originó en el año de 1929.
Kuznets, realizó un informe que incorporó el indicador del PIB (GDP) por sus siglas en inglés para el Gobierno de los Estados Unidos y que representó el primer uso de este indicador.
Kuznets, en varias ocasiones, criticó la utilización de indicadores de crecimiento únicamente para medir la prosperidad económica, a la misma vez, recalcó en varios de sus escritos que no representaban necesariamente el bienestar de los habitantes de las naciones.
Aunque la lógica del indicador PIB no ha cambiado, ha sufrido variaciones menores a lo largo de los años y se ha utilizado de manera global desde 1993, cuando la China adoptó este indicador en su sistema de cuentas nacionales.
En la actualidad el PIB representa la base de los sistemas de cuentas nacionales y es la referencia para medir el crecimiento económico y el volumen de producción de los países del mundo.
Métodos para medir el Producto Interno Bruto PIB
Existen tres métodos básicos para calcular el PIB: el método del gasto (más usado y base de la teoría) y que representa la suma de compras finales en la economía ajustando las exportaciones y las importaciones; el método del valor agregado, que representa la suma del incremento de valor agregado de los subsectores de la economía y el método de los ingresos de los factores de trabajo y capital en la producción.
En teoría, los tres métodos deben generar el mismo resultado.
Método del Gasto para calcular el Producto Interno Bruto
PIB = consumo + inversión + compras del gobierno + (exportaciones – importaciones).
Representa la suma de las demandas finales de bienes y servicios en un periodo de tiempo.
Ejemplo del método del gasto
Supongamos una economía en donde los valores de referencia en millones de unidades son:
| Consumo (C) | 35.5 |
| Inversión (I) | 10.1 |
| Gastos del Gobierno (G) | 8.3 |
| Exportaciones (Xp) | 3.5 |
| Importaciones (Ip) | 4.2 |
Siguiendo el método del Gasto entonces tendríamos:
PIB = C + I + G + (Xp-Ip)
PIB = C (35.5) + I (10.1) + G (8.3) + ( Xp (3.5) – Ip (4.2)
PIB = 53.2 millones de unidades
Método del valor agregado para el cálculo del Producto Interno Bruto
Esta forma de medir el PIB se genera al sumar el valor agregado (definido como la diferencia del valor de mercado de lo que se produce menos los costos de producción o insumos utilizados para crearlo o producirlo), de cada sector de la economía.
Al explicar el método del valor agregado, Sacks, (2013, p. 30), afirma que el método del valor agregado calcula el PIB sumando el valor agregado producido en cada sector de la economía. Así, el PIB es la suma del valor agregado de la agricultura, más el valor agregado de la minería, más el valor agregado de la industria, y así sucesivamente.
El procedimiento consiste en sumar el valor agregado (o la diferencia de mercado entre el valor de los bienes producidos y el costo de haberlos producido) de cada subsector de la economía.
De esta manera:
PIB = suma del valor agregado de cada subsector de la economía.
En términos generales: PIB = SUM (VAB-CI) de cada sector de la economía.
Esto quiere decir que es la suma del valor final de los bienes de cada sector de la economía, restando el consumo intermedio (o los costos de producción) de cada elemento o sector de la economía.
Ejemplo del método del valor agregado
Supongamos que la economía de nuestro país ejemplo cuenta con 8 sectores y se tienen los siguientes datos de valor agregado por sector representados en millones de unidades.
| Sectores de la Economía | Valor agregado por sector |
| Agricultura | 5.5 |
| Minería | 7.8 |
| Industria | 10 |
| Transporte | 7.8 |
| Finanzas | 9 |
| Gobierno | 7.2 |
| Entretenimiento | 2 |
| Educación | 3.9 |
El cálculo del PIB total sería la suma del valor de cada subsector en la economía, es decir, 53.2 millones de unidades, en teoría un valor exacto al cálculo con el método anterior. Cabe aclarar que generalmente las variaciones hacen que los cálculos no sean exactos en el mundo real, por lo tanto, deberían reflejar el mismo resultado del PIB sin importar su forma de cálculo.
Método del ingreso para medir el Producto Interno Bruto
Consiste en sumar los ingresos de todos los factores de trabajo y capital que contribuyen a la producción de la economía, incluidos los impuestos.
De un modo simple, el trabajo (T) es la suma de lo que devengan los empleados produciendo los bienes y servicios y las rentas de capital (C) representan los rendimientos de la economía representada en las utilidades o ganancias sobre los gastos laborales, los impuestos son el aporte de las empresas y asalariados al Gobierno (I).
Para que el cálculo sea preciso se restan los incentivos a la producción o subvenciones y se suman otras rentas generadas, pero el concepto básico es sumar los factores de trabajo y utilidades del trabajo más lo que recibe el Gobierno por impuestos.
PIB = Remuneración de los asalariados (T) + impuestos (I) – incentivos a la producción (IP) + Utilidades generadas por los asalariados (U) + Otros Ingresos (O).
PIB = T + I + U + O – (IP).
Ejemplo del método del ingreso
En la economía de ejemplo tenemos las siguientes cifras respecto a los factores de salarios y capital en millones de unidades.
| Factores de Trabajo y Capital de la economía | Valor |
| Salarios (T) | 35 |
| Impuestos (I) | 5 |
| Incentivos a la producción (IP) | 2 |
| Utilidades generadas por los salarios (U) | 12 |
| Otros ingresos de las personas (O) | 3.2 |
El PIB por el método de los ingresos sería.
Salarios + Impuestos + Utilidades generadas por los salarios + Otros Ingresos – Incentivos a la producción (IP)
PIB = 53.2 Millones de Unidades.
Para tener en cuenta:
El valor total de lo que se produce en la economía, es igual a la suma del valor agregado de los subsectores de la economía y es igual a la suma de los salarios, rentas y capitales que genera la economía.
En otras palabras, las tres formas de medir el PIB deben generar el mismo resultado.
_______
Bibliografía
- Mankiw, Gregory. Macroeconomía. Antoni Bosch. 2014.
- Mankiw, Gregory. Principios de Economía. Paraninfo, 2008.
- Rache de Camargo, Blanca Luz. y Blanco Neira, Gloria Nancy. Fundamentos de Economía, Ideas fundamentales y Talleres de aplicación. Politécnico Grancolombiano, 2010.
- Sachs Jeffrey y Larraín Felipe. Macroeconomía en la economía global. Pearson. 2013.
- Dornbush, Rudiger. Fischer, Stanley y Startz, Richard, Macroeconomía. McGraw-Hill Education. 2014


